
Обработка
Основные понятия
Сценарий - последовательность действий, которые необходимо провести для анализа данных. Сценарий обработки представляет собой комбинацию узлов обработки данных, настраиваемую пользователем для решения конкретной задачи.
Последовательность обработки задается соединением выхода предыдущего узла сценария со входом последующего. Входом и выходом узла являются входные и выходные порты.
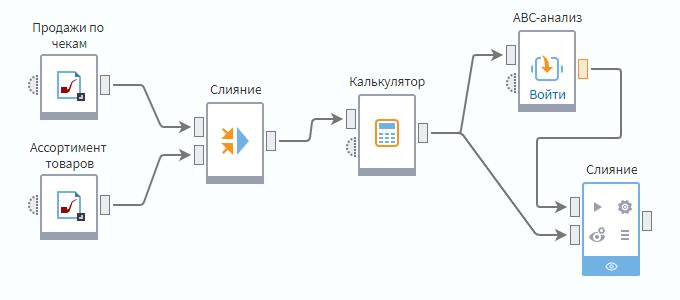
Пример сценария
Узел сценария выполняет отдельную операцию над данными. Перечень возможных операций представлен палитрой готовых компонентов. Таким образом, компонент является прообразом или шаблоном будущего узла сценария. Для того, чтобы создать узел сценария, выполняющий нужную операцию над данными, необходимо мышью перенести соответствующий компонент из панели компонентов в область построения сценария (подробнее см. "Первый сценарий").
Узлы сценария создаются из компонентов 2-х типов:
- Стандартные компоненты - предоставляются в рамках платформы;
- Производные компоненты - создаются и настраиваются пользователем. Производный компонент можно создать из комбинации узлов сценария, реализующей произвольную логику обработки.
Таким образом набор средств для реализации различной логики обработки данных не ограничивается стандартными компонентами платформы и может быть расширен самим пользователем.
Чаще всего для создания производного компонента используется Подмодель. Подмодель является специальным узлом, способным включать в себя другие узлы сценария. Реализованная в Подмодели логика может быть произвольной, при этом разработчик сценария может рассматривать её как «черный ящик».
Подмодель принимает информацию через входные порты, производит обработку и выдает результат на выходные порты. Входные и выходные порты задаются пользователем.
От узла к узлу могут передаваться как наборы данных - таблицы, так и переменные - объекты, содержащие лишь одно значение. Статистические данные таблиц (например, сумма по столбцу, среднее значение и т.д.) при помощи специального компонента могут быть преобразованы в переменные.
Переменные, в свою очередь, могут применяться в узлах для преобразования таблиц. Поскольку таблицы и переменные имеют разную структуру, то соответствующие им порты не могут быть соединены друг с другом и имеют разное обозначение.